Are local LLMs useful yet versus just using ChatGPT and the OpenAI API? Not yet for me but it’s so close and getting easier + faster. It might soon be worth buying a beefed up Mac Mini.
It’s November 2023 and I’m tinkering with https://lmstudio.ai this morning.
I stumbled across LM Studio on Twitter. It’s basically a wrapper that makes it super easy to download and run open-source LLMs locally, including offline. The best feature right now is probably the local-server that you can run which operates just like the OpenAI API — could be great for tinkering with little projects that need a LLM for free!
First step after downloading LM Studio is to pick and download a model from the search bar. There are so many different models, different parameter counts of the same model, different quantizations of the same model-parameter combo, and different file types of the same model-parameter-quantization file. I have no idea what all these mean but it’s fun to dig in.
- I’m running v0.2.8
I first tried downloading a Llama 7B parameter model with a 5_K_M quantization. It runs slowly but it works. It’s pretty wild to see the streaming chat locally! Wow.
- I’m on a M2 Macbook Air with 8GB RAM, so as of now I’m sticking to 7B parameters. Need 16GB RAM to go to 13B.
I tried to use the experimental “Apple Metal” option that is supposed to use the GPU for inference too. With llama 2 chat 7B q5_k_m ggml it crashed but from searching Discord it look like that quantization might not be supported.
- I downloaded two more models:
llama 2 chat 7B q2_k ggmlandllama 2 chat 7B q4_0 ggml - These worked with
Apple Metal (GPU)checked but I also got a pop-up warning saying Metal is not recommended for 8GB RAM (and that having both Metal and mlock (memory lock) enabled can freeze your computer if running with too little RAM or too big a model). It didn’t seem any faster anyway so I stopped using that option.
After testing a couple prompts and quantizations here’s what I’m learning:
- It is WILD to see inference happening locally. Really cool and hard to believe how easy this is.
- Nothing that runs on just 8GB RAM is going to be that useful compared to ChatGPT or an API, even for local projects.
- The quantization makes a big difference on performance — unfortunately, the “model loss” is much greater with fewer-bit quantization, so there’s a clear tradeoff between speed and performance.
- For a hobbyist like me it’s not worth buying a beefed up Mac Mini just to run these bigger models. But I suspect that will change in the next… year or two? The local models will get better, the hardware will get cheaper (maybe, unless demand is so high), and I might have more custom, local scripts for LLMs that are running a lot.
- From how active the Discord is (and others like for GPT4all) it’s clear that there’s lots of people who do find it worthwhile.
- Privacy is the clear reason to use local LLMs.
- I don’t want to send everything to OpenAI and despite claims they aren’t using API calls for retraining, you’re still streaming whatever text to a third-party. I think that eventually a lot of iOS-AI-features will run locally on the iPhone’s hardware, especially with how Apple is posturing as privacy-first.
- Reliability is probably the next strong reason.
- OpenAI and similar providers keep changing and deprecating different API options. I could imagine some SAAS products that have solved a tricky prompt engineering problem might prefer the reliability of a model that’s not changing at all.
- Cost savings is last.
- I’ve spent $19.26 on the OpenAI API since March 2023. And most of that is from when gpt-4 was more expensive. You can buy a lot of API calls for the cost of a M2 Pro Mac Mini 32GB… (1,700+ MSRP). So it’s hard to see this penciling out as cost savings for the hobbyist.
- For a SAAS company, at some scale it might make sense to buy your own machines? But with so much running in the cloud… it’s hard to imagine it’s not better on net to just buy more Azure credits. After all, most company’s don’t run their own servers any more. Why would that change with LLMs? If the cost of electricity and compute are headed to zero, then not because of cost. Maybe there are savings to be had in the sort of messy-middle we’re in currently. But things are moving so fast you might prefer flexibility over any potential, modest cost savings.
Comparing the three models I downloaded
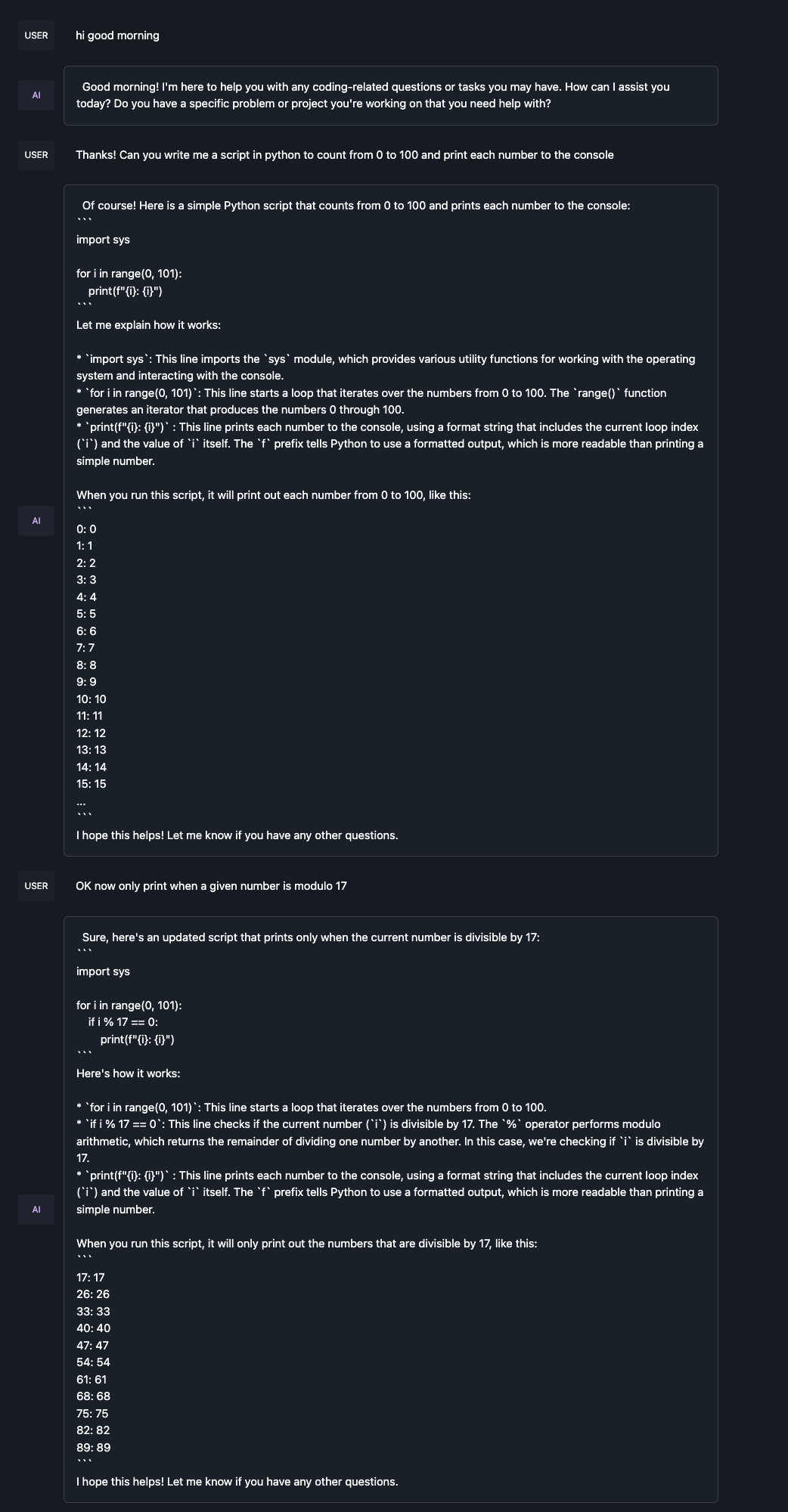
I ran the same three prompts in a row:
- “hi good morning”
- “Thanks! Can you write me a script in python to count from 0 to 100 and print each number to the console”
- “OK now only print when a given number is modulo 17”
| q2_k | q4_0 | q5_k_m | |
|---|---|---|---|
| time to first token | 1.47s | 1.56s | 7.82s |
| total tokens | 317 | 543 | 890 |
| speed | 12.99 tok/s | 8.75 tok/s | 0.72 tok/s |
Running the q5_k_m model basically bricked my computer for multiple minutes during inference. q4_0 was doable. In terms of quality, you can see from the token count that q5_k_m gave much more information and context than q2_k. However, q2_k successfully completed the code. So I can see how with a more complex problem it might be necessary to have a higher quantization. See below for the exact responses. q2_k was pretty helpful here but I’m not sure it would be that helpful for the kinds of tasks I typically use GPT-4 for.
Parameters. What does it actually mean for a model to be 7B versus 13B parameters? Why does the latter take so much more memory to run 13B?
- Parameters are primarily the weights in the neural network. Each parameter is a weight associated with one of the connections between the nodes (neurons) in the network. The model learns the optimal value of these weights during the training process, where it adjusts them to minimize the difference between its predictions and the actual outcomes (training data).
- The more parameters a model has, the more “knobs” that can be adjusted during training. More parameters seems to correlate with better performance, but double parameters doesn’t necessarily double the performance or accuracy. (TODO: Cite a paper here). There are diminishing returns.
- During inference (the process of generating text) the model needs to access all the parameters. This requires not just storing them but also rapidly accessing and performing calculations. So that demands high memory bandwidth. The model is also doing matrix multiplication and other operations that have a high computational load (compared to say just adding integers). The number of operations generally scales with the number of parameters, leading to higher computational costs for larger models.
Quantization. What does this actually mean? Why are there so many different options? Why does it make such a big difference on model performance?
- Quantization involves reducing the precision of the parameters used in the model. For instance, a model might originally use 32-bit floating-point numbers for its weights and activations. Through quantization, these can be reduced to 16-bit, 8-bit, or even lower bit representations. The smaller-bit representation takes up less space and can be processed more quickly. But you lose some of the precision because the range of values that can be represented is narrower.
- For example, consider the number 5.123456. To represent a float in binary you will always have to approximate in some way. There is a standard way to do this in 16-bit, 32-bit, 64-bit, 128-bit.
- 32-bit representation in binary:
0 10000001 01000011111101011100001(IEEE 754 standard) - 8-bit representation in binary:
0 101 0101— there is not a standard way to do this - In this case,
0 10000001 01000011111101011100001is actually 5.13671875 — so close, but not exact.0 101 0101is actually 1.25 which is way farther off. This illustrates the significant precision loss when using 8-bit as opposed to 32-bit representation. - Wait how does that work anyway? In a 32-bit floating-point format (IEEE 754 standard for single-precision), the number is divided into three parts: 1 sign bit, 8 bits for the exponent, and 23 bits for the mantissa.
- Sign bit: 0 (since 5.123456 is positive)
- Exponent: The exponent is calculated to scale the number such that it falls between 1 and 2 (normalized). For 5.123456, the actual exponent is 2, but it’s stored with a bias of 127 in IEEE 754 format, so it becomes 129, which is
10000001in binary. - Mantissa: The mantissa represents the significant digits of the number. For 5.123456 the binary equivalent would be approximately
01000011111101011100001(rounded). - In an 8-bit representation, you have fewer bits for both the exponent and the mantissa.
- 32-bit representation in binary:
- The primary goal of quantization is to reduce the model’s size and computational requirements without significantly compromising its performance. Post-training quantization can take a fully trained model and quantize it down. This is quick because it doesn’t require actual retraining. But the drop in accuracy could be higher than other methods (e.g., incorporating quantization directly into the training process)
- Quantization down to 8-bit and 4-bit is what makes it possible to run a model locally (Quantize Llama models with GGML and llama.cpp | Towards Data Science)
- The other parts of the suffix refer to various quantization methods, such as using different quantization for different tensors (e.g., attention.vw, feed_forward.w2, attention.wv, and attention.wo). These are different parts of the model’s architecture. For example, tensors related to attention mechanisms help the model determine which parts of the input text are most relevant at different stages of processing.
- In general a tensor is a mathematical object — you can think of this as a generalized form of scalars, vectors, and matrices. Tensors can be of various dimensions: a 0-dimensional tensor is a single number (scalar), a 1-dimensional tensor is a vector, a 2-dimensional tensor is a matrix, and higher-dimensional tensors can have 3 or more dimensions. In LLMs, tensors are used to represent various types of data, including the input text, model weights, biases, and the hidden states generated during the processing of the text.
- How do parameters and quantization interact? From Discord: “As a rule of thumb: a Q4 of the higher-parameter model will outperform the Q8 of the lower-parameter version. It’s not an exact science and it totally depends on your use case but that’s the best I can do in a short answer”
GPU vs. CPU. What does it actually mean to use the GPU for inference too, versus just the CPU?
- CPUs (Central Processing Units) are designed for general-purpose computing and optimized for sequential processing. Each core can handle one or two threads at a time, making them efficient for tasks that require complex, sequential processing. When using a CPU for inference, the model’s computations are performed sequentially or with limited parallelism.
- GPUs (Graphics Processing Units) are designed for highly parallel processing. They excel at handling multiple operations simultaneously, which makes them ideal for the matrix and vector operations common in deep learning. GPUs have hundreds to thousands of smaller cores designed for handling multiple tasks in parallel. Using a GPU for inference means leveraging this parallel processing capability. It allows for the simultaneous computation of different parts of the neural network, significantly speeding up the process.
- When running a LLM locally, you usually load the model’s architecture and weights into memory and then it’s possible to explicitly move the model and processing to the GPU while doing inference.
- That’s different for newer Macs. The Apple M1 and M2 chips are built on the ARM architecture, which is different from the x86 architecture used by Intel and AMD CPUs. ARM is known for its efficiency and lower power consumption. These chips are “System on a Chip” (SOCs) they integrate the CPU, GPU, Neural Engine, I/O, and more onto a single chip. So there’s no need to “switch to GPU” — but there might be optimizations that better take advantage of what the ARM architecture offers.
The Bloke. Who the heck is this??
- If you search for a model in LM Studio, most of them are uploaded to Hugging Face by a user named TheBloke. This is Tom Jobbins , a “purveyor of fine local LLMs” (TheBloke (Tom Jobbins) · GitHub) who is working to make it easy for people to try large language models at home. He’s uploaded almost 3,000 models to Hugging Face!!
Comparing responses from the 3 models
q2_k
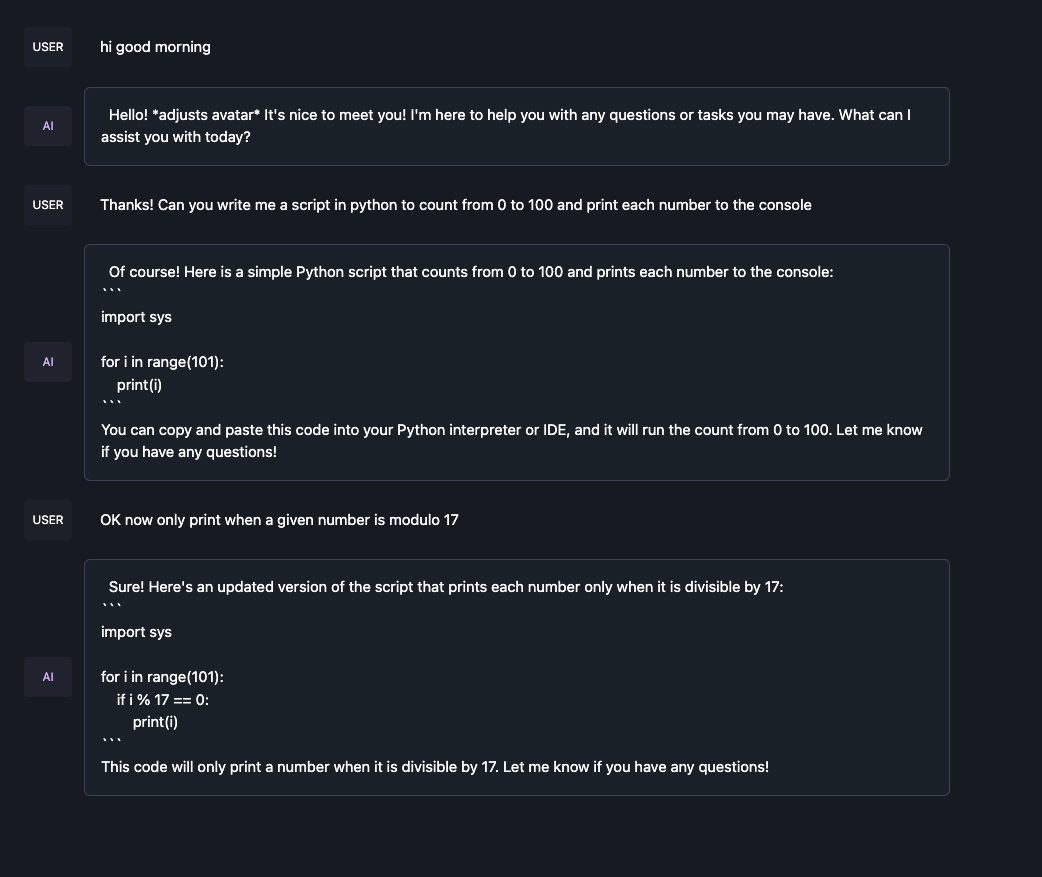
q4_0
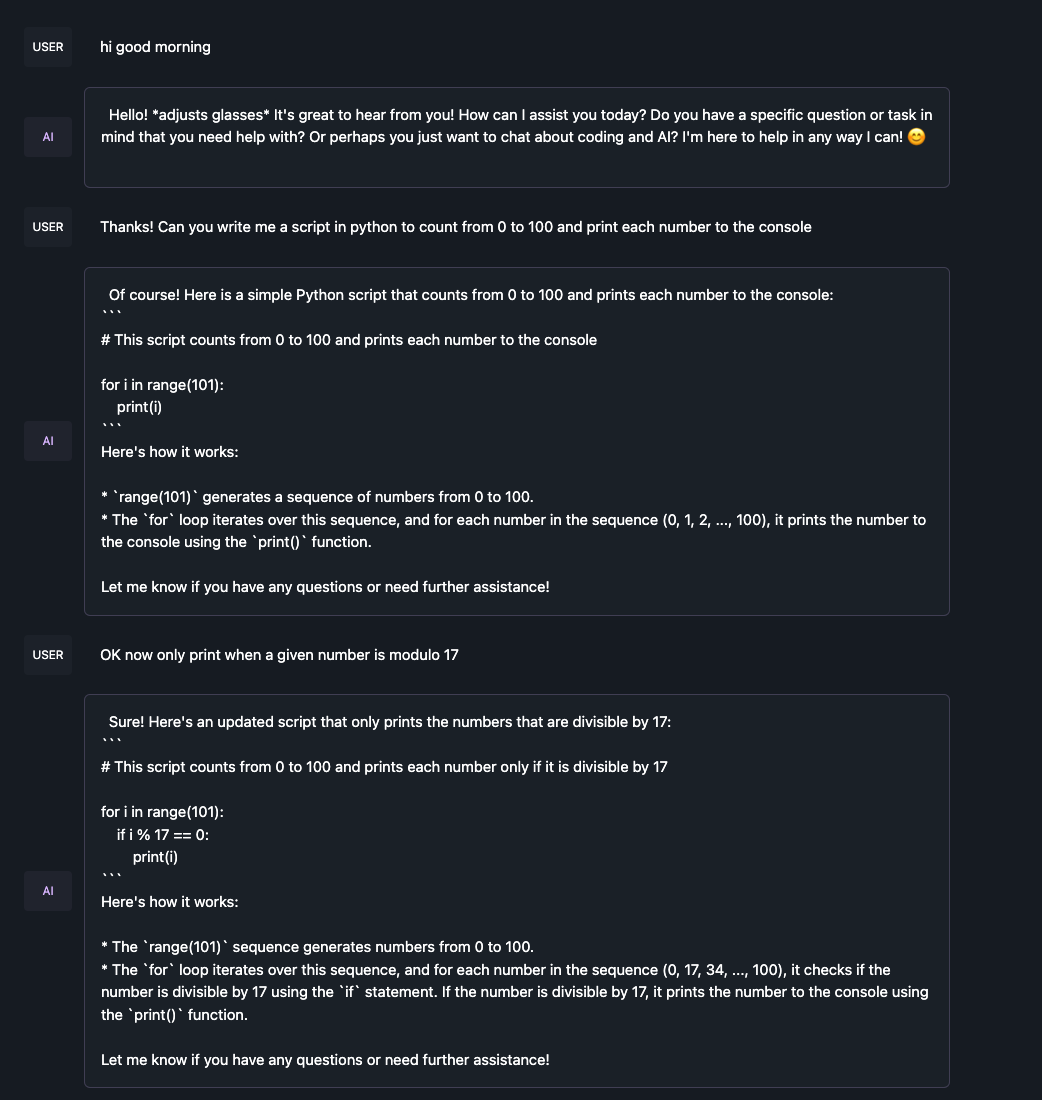
q5_k_m